Whether you work in marketing, sales, or data engineering, you most likely use several apps or services for collecting and storing data from different sources. To boost productivity and reduce errors, you can automate various tasks in each system – from lead capturing in CRMs to e-commerce workflows and data processing pipelines.
But the challenge is consolidating data across different sources so that the information is consistent within all systems. Data synchronization is a process that ensures your data is up-to-date, relevant, and complete, thus helping you make informed decisions for your business. And this process, too, can be automated!
Data from two systems can be synced in one direction (one-way sync) or in two directions (two-way sync). In n8n, the Merge node can help in the process of syncing data. This node allows you to choose between eight different ways of merging data from two sources in order to then synchronize them.
In this tutorial, you’ll learn step-by-step how to build one-way sync and two-way sync workflows with no code in n8n. The use case for this post is synchronizing data between two CRMs (Pipedrive and HubSpot), but the underlying principle can be applied to any other apps.
Workflow prerequisites
The workflows presented in this post are available on our workflows page. If you want to follow along with the tutorial, you need to have:
- n8n set up. You can either install the desktop app (for Mac or Windows), sign up for a cloud instance, or set up n8n locally
- Pipedrive and HubSpot accounts and credentials
One-way synchronization
In one-way sync (unidirectional sync), information is updated only in one direction. Practically, data are added/updated from a primary location (source) to a secondary location (target) in one direction, but no files data are ever copied back to the primary location.
A one-way sync is useful when information like Contacts or Orders are only ever updated in your source system, or when you back up files. In this case, we say that the source is mirrored to target, as the secondary location is in sync with the primary location.
Next, we’ll put the theory into practice and implement a no-code, one-way sync workflow in n8n.
One-way sync workflow: Sync contacts from Pipedrive in HubSpot
Let’s consider a common business use case: storing information about customers (such as contact name and email) in two CRMs, for instance, Pipedrive and HubSpot.
This workflow syncs contact information from Pipedrive to HubSpot, so that when the information is updated in Pipedrive, then it’s updated in HubSpot as well. The workflow for this use case looks like this:
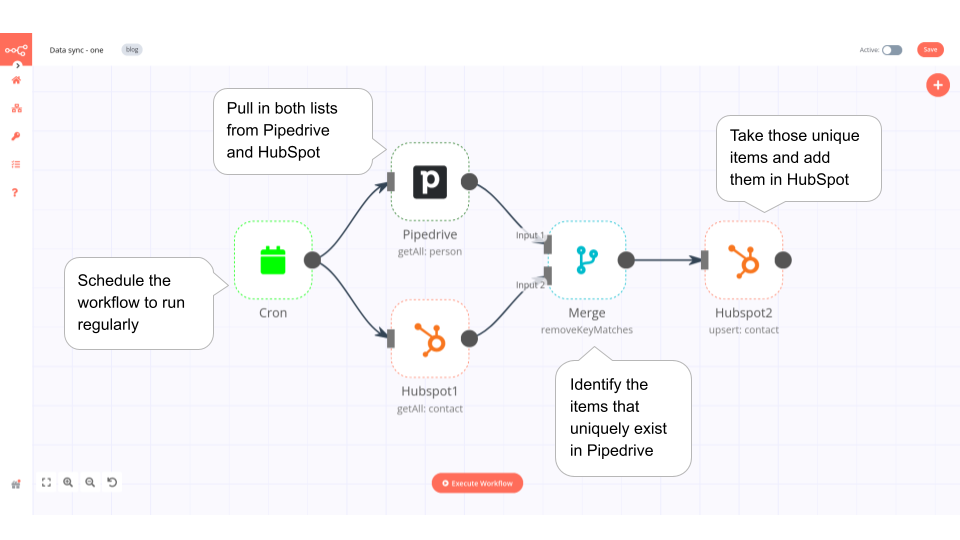
1. The Cron node schedules the workflow to run every minute.
💡 Schedule or trigger the workflow*: Note that for this use case, you can have a workflow with the *Pipedrive Trigger node, which triggers the workflow any time information is updated in Pipedrive. But if you need to sync data between apps or services that don’t have an n8n Trigger node, you need to use the Cron node as a trigger.
2. The Pipedrive and Hubspot1 nodes pull in both lists of persons from Pipedrive and contacts from HubSpot.
3. The Merge node with the option Remove Key Matches identifies the items that uniquely exist in Pipedrive.
4. The Hubspot2 node takes those unique items and adds them to HubSpot.
Now let’s see how to set up each node.
1. Get data from the source CRM
In the Pipedrive node, add your credentials in the Pipedrive API section. Then, configure the following parameters:
- Resource: Person
- Operation: Get All
- Return All: Toggle to True
2. Get data from the target CRM
In the HubSpot node, add your credentials in the HubSpot API section. Then, configure the following parameters:
- Resource: Contact
- Operation: Get All
- Return All: Toggle to True
In HubSpot, we have three contacts, which are also in Pipedrive. We want to add the fourth person from Pipedrive into HubSpot.
3. Merge data from source and target CRMs
Now that the data is all set, it’s ready to be merged. For our use case, we want to identify contacts that exist only in Pipedrive and add them to HubSpot.
In a one-way sync workflow, it’s important to know clearly from the beginning which system serves as the source, as that would be Input 1 (in our case, Pipedrive). The target system would then be Input 2 (in our case, HubSpot).
The Merge node receives data from Input 1, goes back to Input 2 and executes the node(s) in order, then outputs the merged data from Input 1 and Input 2.
To match data between two systems, the Merge node needs a piece of information that is present in both systems, to serve as a reference. This reference is a key column – a common column between the two tables that contains key values, which uniquely identify rows in the table.
For this reason, the key values must be different in each row. The key column can be, for example, the customer’s email address, an SKU, or the order number.
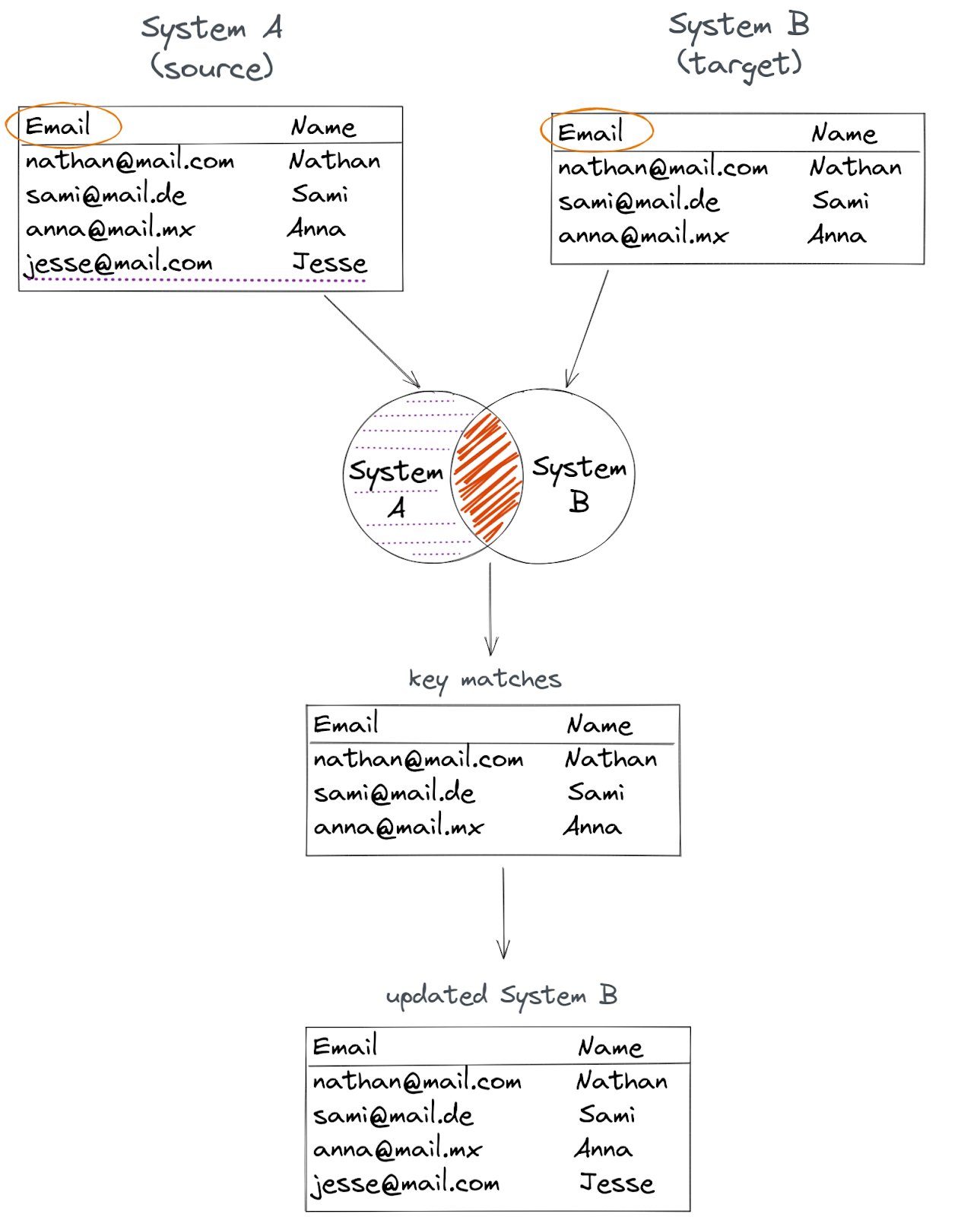
In our case, the key column between Pipedrive and HubSpot is email, so we’ll merge data based on this column.
Back to the workflow, in the Merge node, configure the following parameters:
- Mode: Remove Key Matches
This operation keeps data of Input 1 if it doesn’t find a match with an item of data from Input 2. - Property Input 1: email[0].value
- Property Input 2: identity-profiles[0].identities[0].value
The source key column is passed in Property Input 1 and the target key column is passed in Property Input 2.
💡 For Property Input 1 and Property Input 2, you need to enter the property key in dot-notation format (as text, not as an expression).
What is dot-notation?
In n8n, all the data that is passed between nodes is an array of objects. When you execute a node, the returned data is displayed in Table view and JSON view.
Dot notation is a way to access the properties of an object. The dot-notation syntax is object.property, so the reference is made from outermost to innermost.
In the example above, the object (column name) email contains three properties: label, value, and primary. To reference the email value (email address), we write the dot notation email[0].value. The [0] references the first item of the email array.
The merge operation Remove Key Matches returns the data of three contacts.
4. Update data in the target CRM
Once the data is merged, you need to update the information in the target system (HubSpot).
To update contact information in HubSpot, configure the following parameters in the HubSpot node:
- Resource: Contact
- Operation: Create/Update
- Email > Add Expression > Current Node > Output Data > JSON > email > [Item: 0] > value:
{{$json["email"][0]["value"]}} - Additional Fields > Add Field > First Name > Add Expression > Current Node > Output Data > JSON > first_name:
{{$json["first_name"]}}
Two-way synchronization
In a two-way sync (or bidirectional sync), information is updated in both directions. This means that if the information is updated in the first location, then it will be automatically updated in the second location as well – and vice-versa. This is assuming that both systems are actively used, so users can enter data in both systems.
A two-way sync is useful when two different systems are actively used to store information, for example, if one system offers more features that are relevant for the sales team, but the relevant company-wide information is stored in another system. In this case, we say that the two systems are equivalent.
Let’s see what this looks like in action in a workflow that synchronizes data between Pipedrive and HubSpot, extending the one-sync workflow above.
Two-way sync workflow: Sync contacts between HubSpot and Pipedrive
In this workflow, the information about Pipedrive persons and HubSpot contacts (their name and email) is updated in both Pipedrive and HubSpot when you make changes in either source.
In a two-way sync workflow in n8n, you essentially have two parallel workflows, each including a Merge node that takes input from the opposite and inline workflow. For our use case, the workflow looks like this:
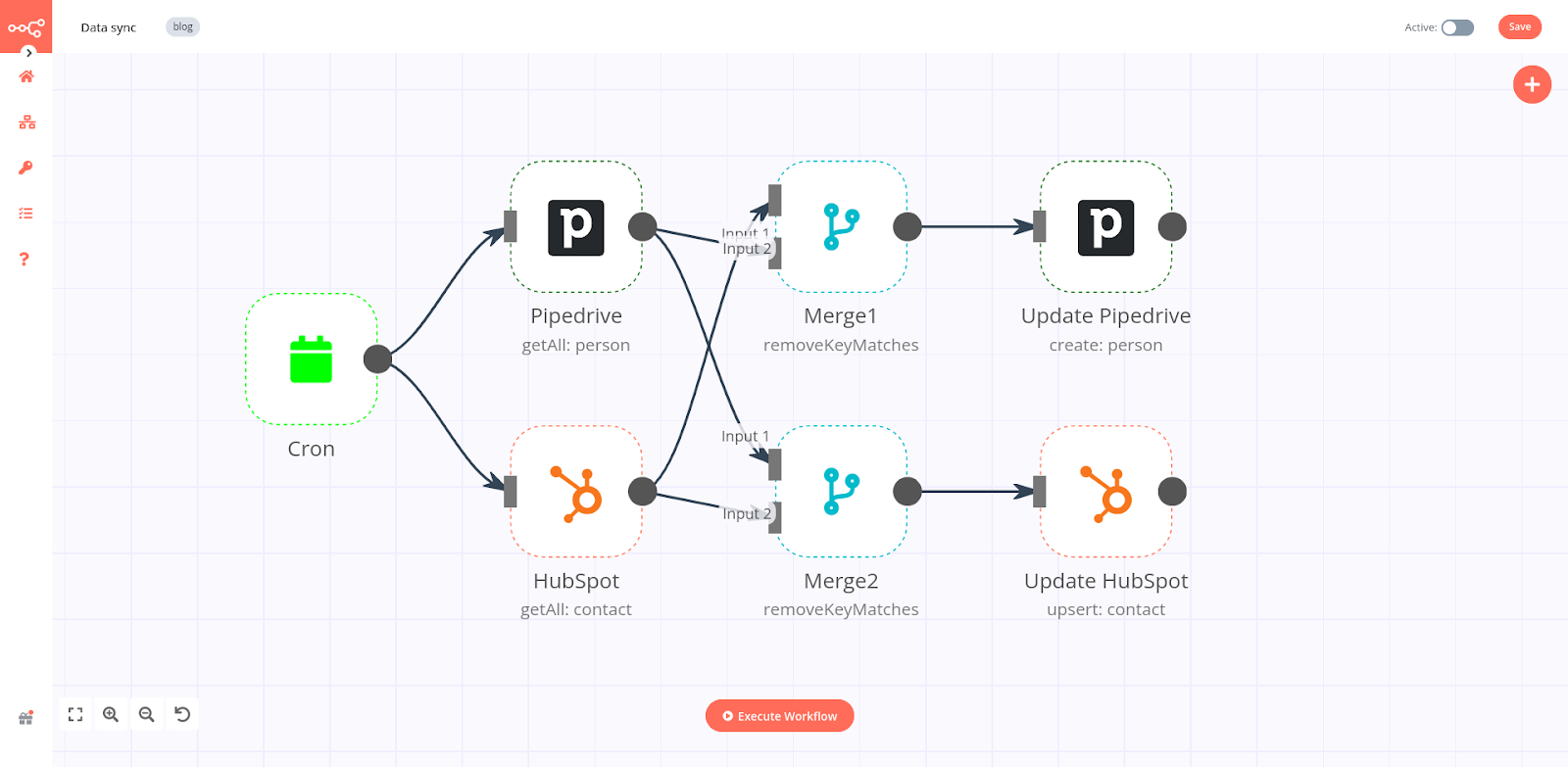
The first part of the workflow starts with the Pipedrive node, which fetches the data when information about a person is updated in the CRM. The second part of the workflow starts with the HubSpot node, which fetches the data when information about a contact is updated in HubSpot.
- The Cron node schedules the workflow to run every minute.
- The Pipedrive and Hubspot nodes pull in both lists of persons from Pipedrive and contacts from HubSpot.
- The Merge1 and Merge2 nodes with the option Remove Key Matches identify the items that uniquely exist in HubSpot and Pipedrive, respectively.
- The Update Pipedrive and Update HubSpot nodes take those unique items and add them in Pipedrive and HubSpot, respectively.
Now let’s see how to set up each node.
1. Get data from both CRMs
The setup of the Pipedrive and HubSpot nodes is the same as in the one-way sync workflow above.
In the Pipedrive node, configure the following parameters:
- Resource: Person
- Operation: Get All
- Return All: Toggle to True
In the HubSpot node, configure the following parameters:
- Resource: Contact
- Operation: Get All
- Return All: Toggle to True
2. Merge data from the two CRMs
To merge data from Pipedrive and HubSpot, you need to use two Merge nodes, one for each system.
The first Merge1 node is connected to Pipedrive, so it takes Input 1 from HubSpot and Input 2 from Pipedrive. In the Merge1 node, set the following parameters:
- Mode: Remove Key Matches
- Property Input 1: identity-profiles[0].identities[0].value
- Property Input 2: email[0].value
The second Merge2 node is connected to HubSpot, so it takes Input 1 from Pipedrive and Input 2 from HubSpot. In the Merge2 node, set the following parameters:
- Mode: Remove Key Matches
- Property Input 1: email[0].value
- Property Input 2: identity-profiles[0].identities[0].value
3. Update data in both CRMs
Once the data is merged, you need to update the information in both systems.
To update person information in Pipedrive, configure the following parameters in the Pipedrive node:
- Resource: Person
- Operation: Create
- Name > Add Expression:
{{$json["properties"]["firstname"]["value"]}} - Additional Fields > Email > Add item > Add Expression:
{{$json["identity-profiles"][0]["identities"][0]["value"]}}
To update contact information in HubSpot, configure the following parameters in the HubSpot node:
- Resource: Contact
- Operation: Create/Update
- Email > Add Expression:
{{$json["email"][0]["value"]}} - Additional Fields > Add Field > First Name > Add Expression:
{{$json["properties"]["firstname"]["value"]}}
Now both Pipedrive and HubSpot contain the latest, up-to-date information about contacts.
What’s next?
In this tutorial, you’ve learned how to build one-way and two-sync workflows to synchronize data between two CRMs. You can further adapt these workflows for different business needs.
For example, you can sync data between different databases like Postgres or MongoDB, sales data between Salesforce and Shopify, or marketing data between Google BigQuery and MailChimp.
This post was originally published on the n8n blog.